By: Bhavesh Patel | Updated: 2017-11-08 | Comments (14) | Related: More > Integration Services Data Flow Transformations
Problem
We have a need to synchronize data in tables across SQL Server instances. There are multiple ways this can be done such as using link servers, replication, TableDiff utility, etc., but in this tip I am going to demonstrate one-way synchronization using an SSIS Merge Join.
Solution
I have two SQL Server instances: serverA and serverB. I also have two different databases, TestingA on serverA and TestingB on serverB. Both of these databases have the same data in table Customer_Detail with a unique key of custID. Then we changed some of the data on serverA and now I want the data on serverB to be the same for reporting purposes, so based on that I will demonstrate how to synchronize this data from serverA to serverB using a Merge Join in SSIS.
Below is what my SSIS Package looks like. I will discuss each of the steps in the package.

Step 1: Initiate SQL Connections
I have two OLE DB Sources, one for serverA (source) and the other for serverB (destination). Below are how these connections are setup.
Source connection: serverA
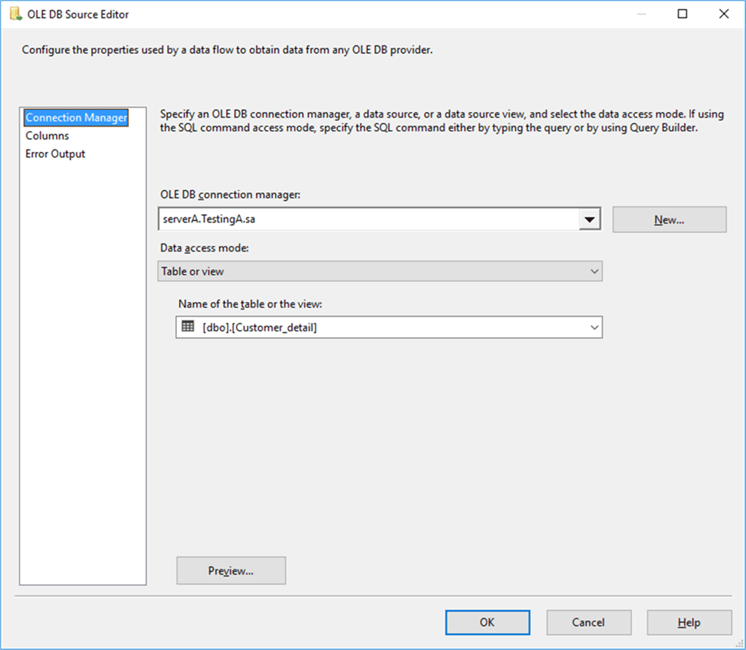
Source connection: serverB

Step 2: Apply sorting on tables
When applying a Merge Join, the data needs to be sorted for both inputs, hence I am applying a sort operation to both sides. An alternative to this step is to pre-sort the data in a query and use a SQL command instead of table. This needs to be done for both inputs.

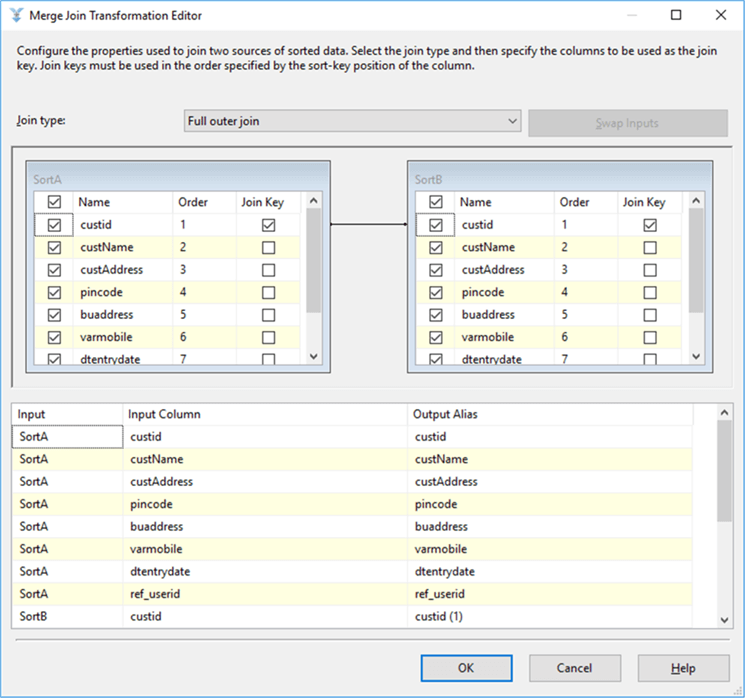
Step 3: Applying Merge Join
I have applied a full outer join on the unique column custid in the Merge Join. I need to get NULL records from the right and left tables where the custid does not match and this will determine if we need to perform a delete or insert operation.
Step 4: Split the Records
In the next step, I have applied a conditional split. I have added three different conditions based on the full outer join result. These are the three conditions:
- UPDATE (custID match): If the custID exists on both the source and destination then we do an update.
- INSERT (custid not found in destination): If custID is found only on the left (source) then we need to insert this data into the destination table.
- DELETE (custID is not found in source): If custID is not found in the source table then we need to delete this data from the destination table.

Step 5: Find Updated Record
As mentioned above the UPDATE (custID Match) condition, it returns the data where custID matches. We don't know if the data has changed on the source, so to minimize updating every record I have added a conditional split that compares each column to see if any data is different. If it is, then we will do the update and if not we will not update the record. Only the records that are different will go to Step 6.
Condition

Step 6: Performing Insert, Update and Delete to Destination Table
So we now have three streams of data to do either an Insert, Update or Delete.
Insert Records
I have an OLE DB Destination connection object Customer_detail and mapped the input columns as follows.


Update Records
For updating the data, I have an OLE DB Destination connection and added a sqlcommand as follows using the Advanced Editor.
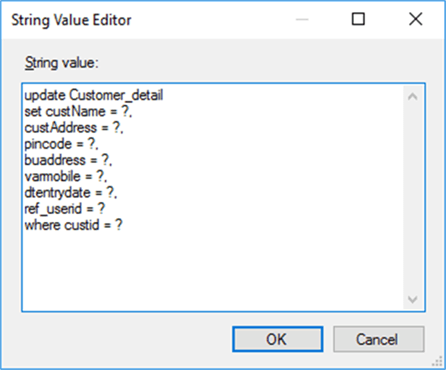

After initiating the command with parameter “?”, I then applied the input column mapping with available parameter destination columns based on the destination table.

DELETE Records
For deleting data, I have an OLE DB Destination connection and added a sqlcommand as follows using the Advanced Editor.


For the delete record the column mapping is as follows.

Running the Package
After setting up all of the above steps, randomly changing some of the data, I then run the package and get the following.

Conclusion
As per the above package synchronization, I have performed insert, update and delete operations with data from the source to the destination. In SSIS, there are also other methods available for synchronization data such as using the tablediff utility in SSIS. I suggest you find the method that works best for your business needs.
Next Steps
- Test in your development environment prior to rollout in production.
- Checkout these other Server Integration Services Development Tips






About the author
 Bhavesh Patel is a SQL Server database professional with 10+ years of experience.
Bhavesh Patel is a SQL Server database professional with 10+ years of experience.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2017-11-08
